計画停電における情報提供のうち、もう 1 つの問題点は、ファイルが PDF 形式になっていたことだ。
PDF(Portable Document Format)は、作成した文書を異なる環境(OSや端末)でも元レイアウト通りに表示・印刷することを目的として、アドビ システムズが開発したデータフォーマットだ(2008 年には ISO(国際標準化機構)において標準化されている)。PDF ではフォントを文書に埋め込むこともできるため、元文書の再現性は非常に高い。元データを改ざんしにくいという特徴もあるため、出版・印刷分野での校正やデータの入稿、企業や官公庁での文書配布などに広く使われることになった。
数多くの長所を備える一方、PDF には短所もある。まず、PDF では文書としての見た目を優先しており、コンピュータでの自動処理についてはあまり考慮されていない。
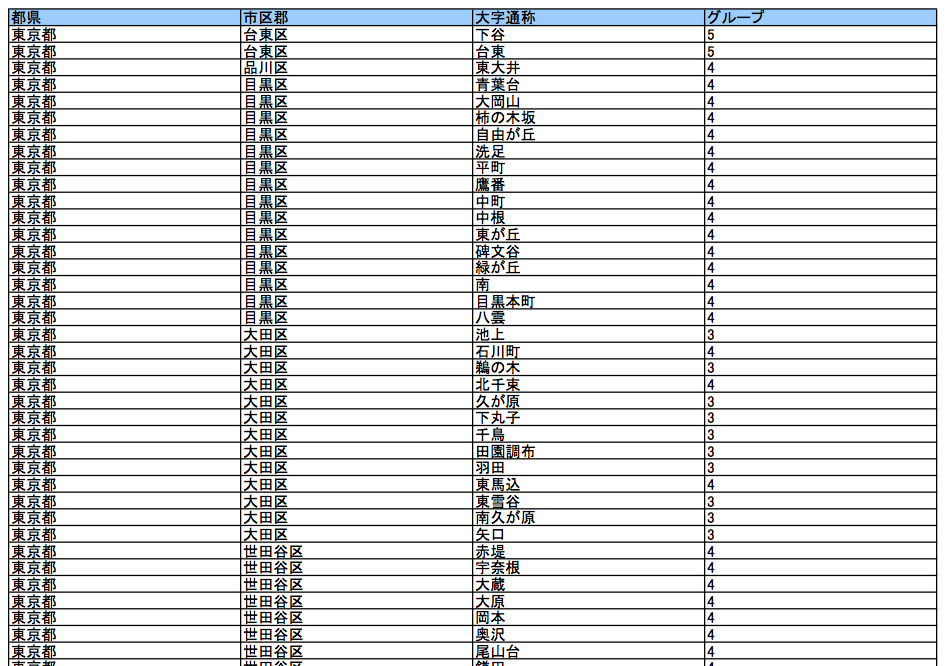
例えば、見た目がまったく同じ複数の表が PDF 形式で提供されていたとする。見た目が同じなら、人間が読む分には何の支障もない。しかし、1 つの表は、ワープロソフトを使って罫線文字(├ ┤ └などの文字)を使って体裁を整えているのかもしれない。空白文字を入れて、空きを調整しているかもしれない。複数行にわたっている項目は、改行を入れているのか入れていないのかもわからない。PDF では見た目が同じでも、含まれているデータはまったく異なる構成になっていることがある。
また、PDF の仕様は複雑であり、閲覧・編集するためのソフトによっても挙動が変わってくる。一続きになっている段落をまとめてコピー&ペーストしようとしても、必ずしも意図通りに文字を選択できるとは限らない。
阿部秀彦を始めとする Google の地図関連エンジニアたちは、電車運行情報などさまざまな災害関連情報を地図上に表示してユーザーに提供していた。計画停電についても、東京電力提供の PDF から住所やグループ番号を抽出して地図上にマッピングしようとしていたが、この作業にはかなり手こずったという。表が複数ページに分かれている場合や、項目が改行で区切られている場合など、複雑な条件を解析するスクリプト(プログラム)を書き、作業を進めていった。苦労の末、16 日(水)には、Google マップ上で計画停電の地域を地図上で確認できる「停電マップ」が公開された。
計画停電の開始から数日後には、東京電力から PDF と共に、元データの Excel ファイルも提供されるようになったが、この処理も難物だった。一見データが整然と並んでいるようでも非表示の列があったり、ファイルによって項目名がいきなり増えるということもあった。表の形式も統一されておらず、地域によって専用のスクリプトを書く必要もあったという。
 Crisis
Response
Crisis
Response