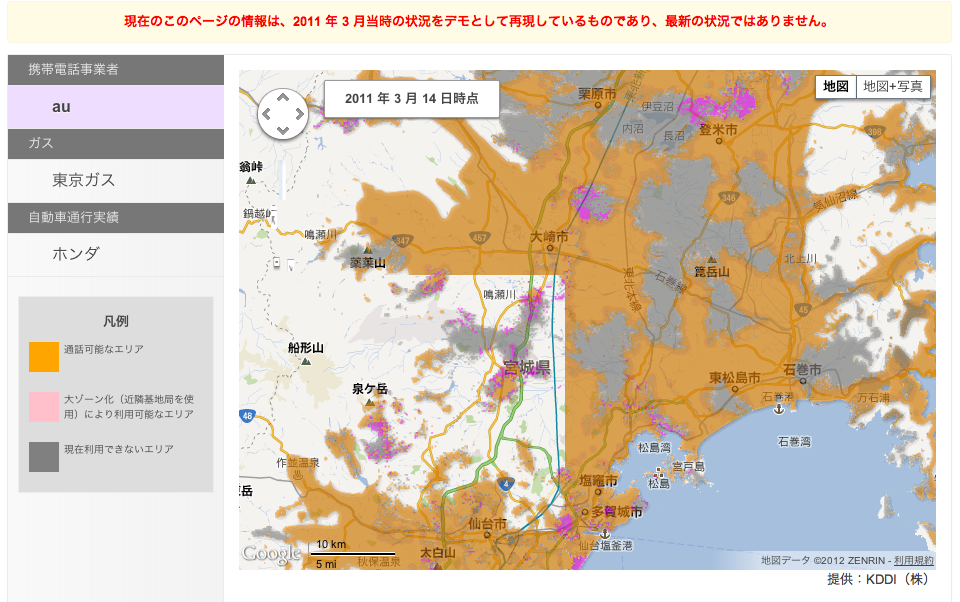
Crisis
Response
Crisis
Response
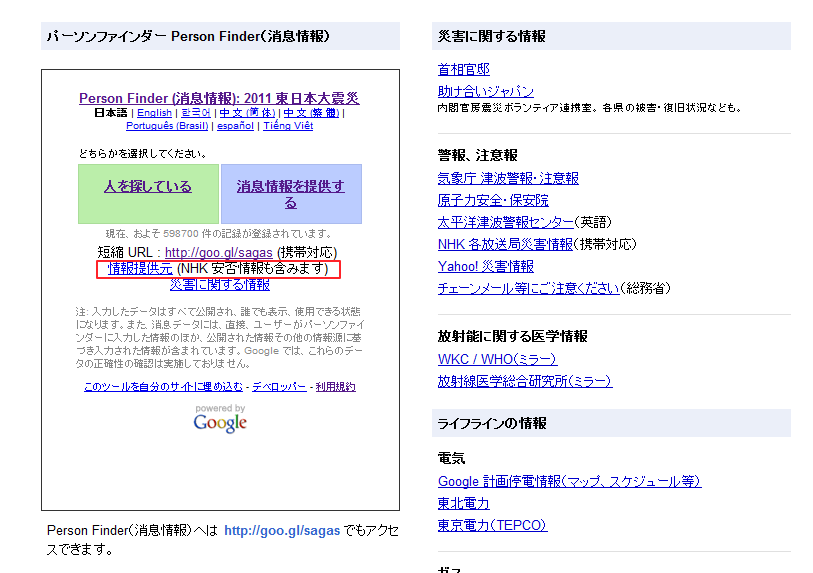
東日本大震災において、最終的なデータ登録件数が 67 万件にも上ったパーソンファインダーだが、情報源は大きく分けて 3 つあった。1 つは、個人ユーザーがそれぞれ手入力したデータ。もう 1 つは、前回紹介した避難所名簿の写真を元にしてボランティア達がテキスト化していった 14 万件のデータ。そして、3 番目がマスメディアや関係機関との提携によって登録されたデータである。登録件数でいえば 3 番目のデータは、67 万件のうち 3 割程度を占める。しかし、こうした提携関係は、東日本大震災以前から築かれていたものではなかった。
3 月 14 日(月)の午前 2 時に避難所名簿共有サービスを開始した後、Google 社員達はより多くの安否情報を検索できるようにするため、マスメディアとの連携を模索し始めた。ふだんからメディア関係者とのパイプ役になっている、広報部マネージャーの富永紗くらは面識のあった記者を通じて NHK にコンタクトを取った。
震災直後から NHK では、テレビやラジオで安否情報の提供を呼びかけており、視聴者から多くの情報が寄せられていた。NHK ではテレビのテロップ等でこれらの情報を流していたが、テレビやラジオでは後から情報を検索することができない。視聴者は自分の地域の情報が流れるまでテレビの前に座って待っていなければならなかった。担当者らは効果的に情報を検索してもらえる方法を探していたが、自前で一から検索システムを開発するのは無理がある。そこに、タイミングよくパーソンファインダーというソリューションが登場したわけだ。
NHK との担当者と、パーソンファインダーのプロダクトマネージャーを務めることになった牧田信弘、パートナーシップ担当の村井説人らは即日に打ち合わせを行った。翌 15 日(火)にはソフトウェアエンジニアの竹内淳平も参加して表示する際の文言などの細部を詰め、早くも 16 日(水)には NHK から Google にデータを提供することが決まった。平常時には考えられない異例のスピードで、パートナーシップは進められていった。
作業を効率化するため、竹内らは海外オフィスのエンジニアとも協力して、データの重複をチェックするスクリプト(プログラム)などを次々と書いていった。NHK からデータが届くと、スクリプトを走らせてデータチェック、パーソンファインダーに登録して公開するというサイクルをスムーズに回せるようになった。